Torch Databricks Integration
Integration Modes
Torch can be integrated with Databricks in two modes based on where the Spark jobs run
- External Spark Cluster with Databricks Delta lake as the data source.
- Full Databricks integration (Data and Compute both on a Databricks cluster)
External Spark Cluster with Databricks Delta lake as the data source
In this mode, the installation process is the same as that of normal Torch installation (https://docs.acceldata.dev/docs/torch/overview/installation), and Databricks Delta lake can be added as one of the datasources using Torch Databricks connector. The Spark jobs will run on an external Spark cluster running either on Kubernetes or Spark on a Hadoop Cluster. Here Databricks will just be added as a datasource to access data from Databricks Delta tables for profiling and Quality Evaluation. To add Databricks as a datasource, Torch needs Databricks cluster JDBC details, along with UID and Personal Access Token to establish the connection, and to run queries.
The JDBC details for a cluster can be found on the Advanced Options in Cluster Details page.
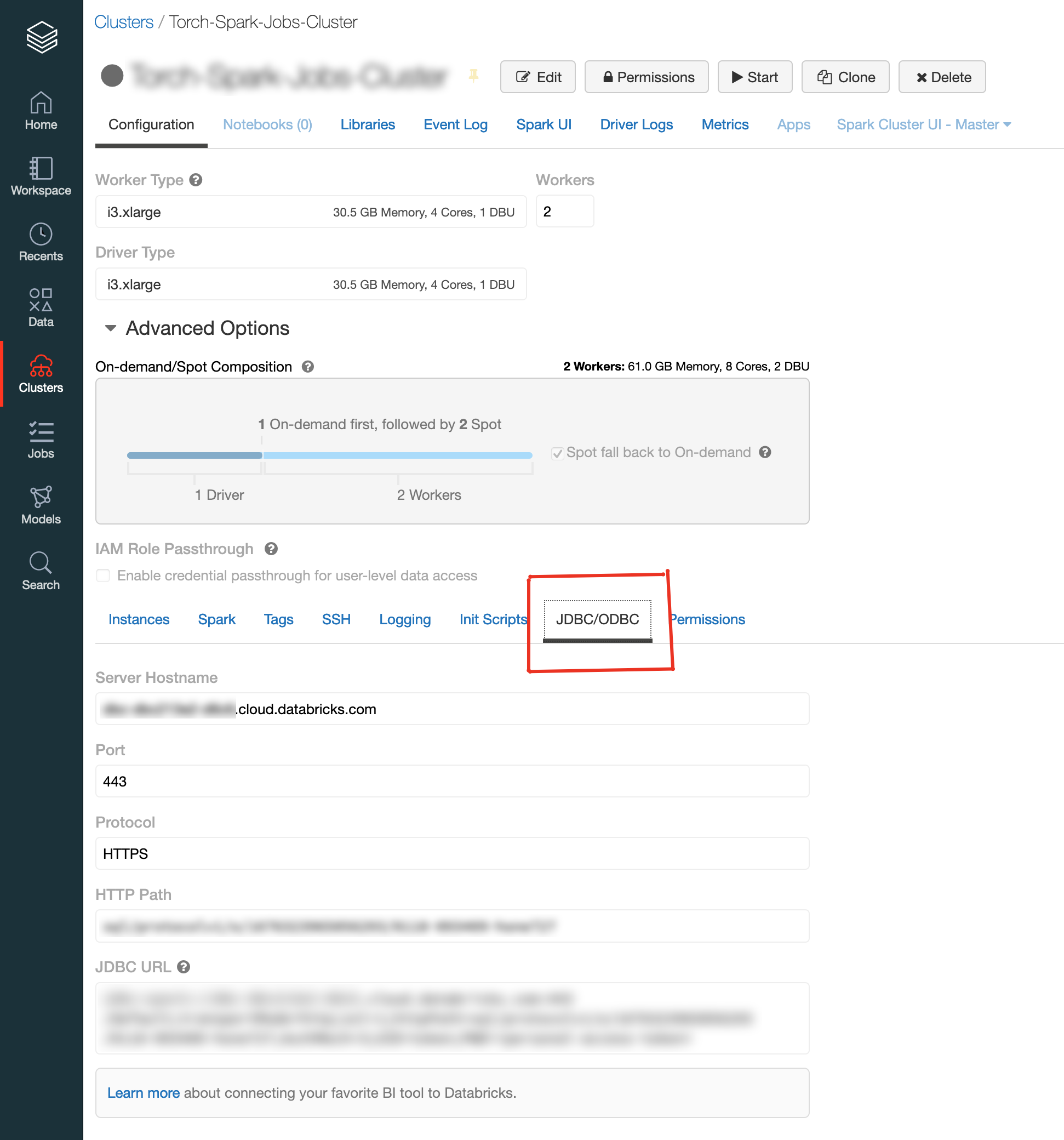
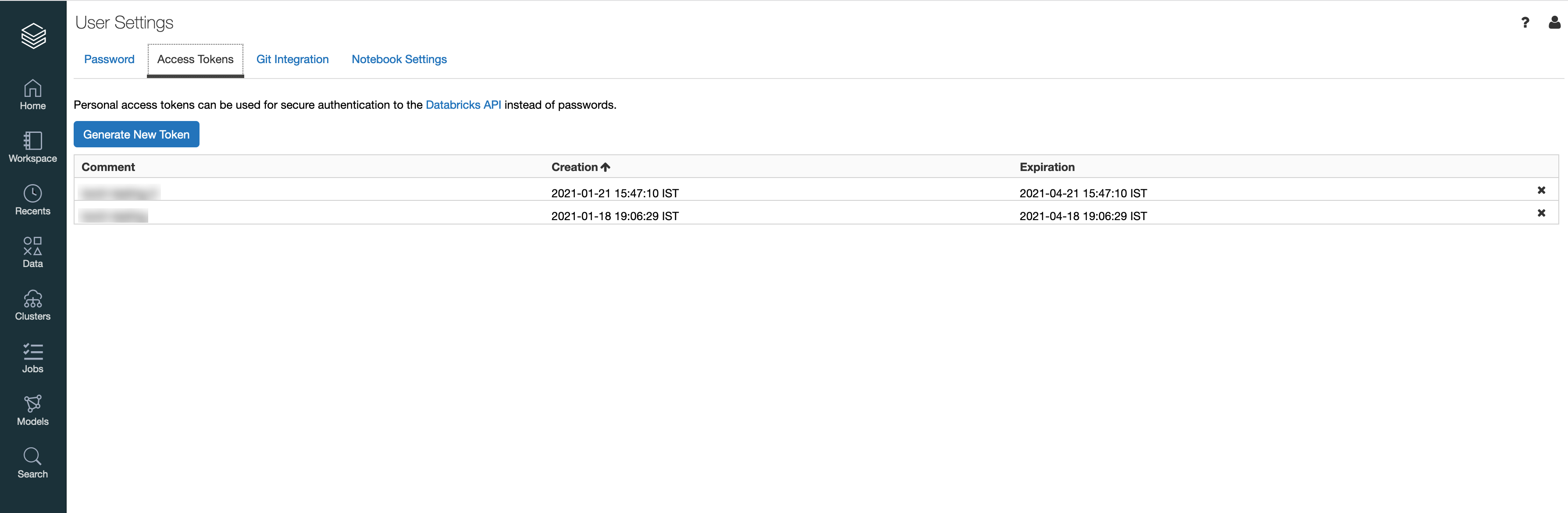
Here UID will be "token" , PWD is the Personal Access Token , which can be generated on User Settings page on Databricks.
Adding Databricks Datasource
Get the JDBC URL of the Databricks Cluster along with Access Token. The UID will be "token" by default. Sample JDBC URL below:
jdbc:spark://dummy.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/16763 040399-dummy267;AuthMech=3Go to Datasources on Torch UI, click on Create Datasource and choose Databricks. Provide the necessary connection properties such as JDBC URL, Username and Password.
URL will be the JDBC URL ex: jdbc:spark:/dummy.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/138694 040399-dummy267;AuthMech=3Username - "token"Password - Personal Access TokenTest the connection and proceed if it succeeds.
Start the crawler to crawl the Databricks assets.
Full Databricks Integration
In this mode the analysis jobs will run on Databricks cluster. Along with other supported datasources, Torch can consume Databricks Native Spark tables as well as Delta lake tables for Quality Evaluation and any other Torch supported feature executions. To enable full Databricks integration, torch needs:
- Cluster URL, UID and Personal Access Token having access to submit the jobs and run queries.
- A path on DBFS to upload the torch binaries.
- An S3 bucket to store the torch internal results and this S3 bucket should be mounted on a path on DBFS. Ability to store torch internal data on DBFS will be provided soon, in which case mounting S3 will not be mandatory.
important
Please follow https://docs.databricks.com/administration-guide/access-control/index.html to manage access and personal access tokens
The following pre-requisites are required to integrate Torch on Databricks cluster:
Upload ad-analysis-app.jar to a specific location on DBFS Example: In the below picture, the ad-analysis-app.jar is uploaded to
/databricks/acceldatafolder on DBFS.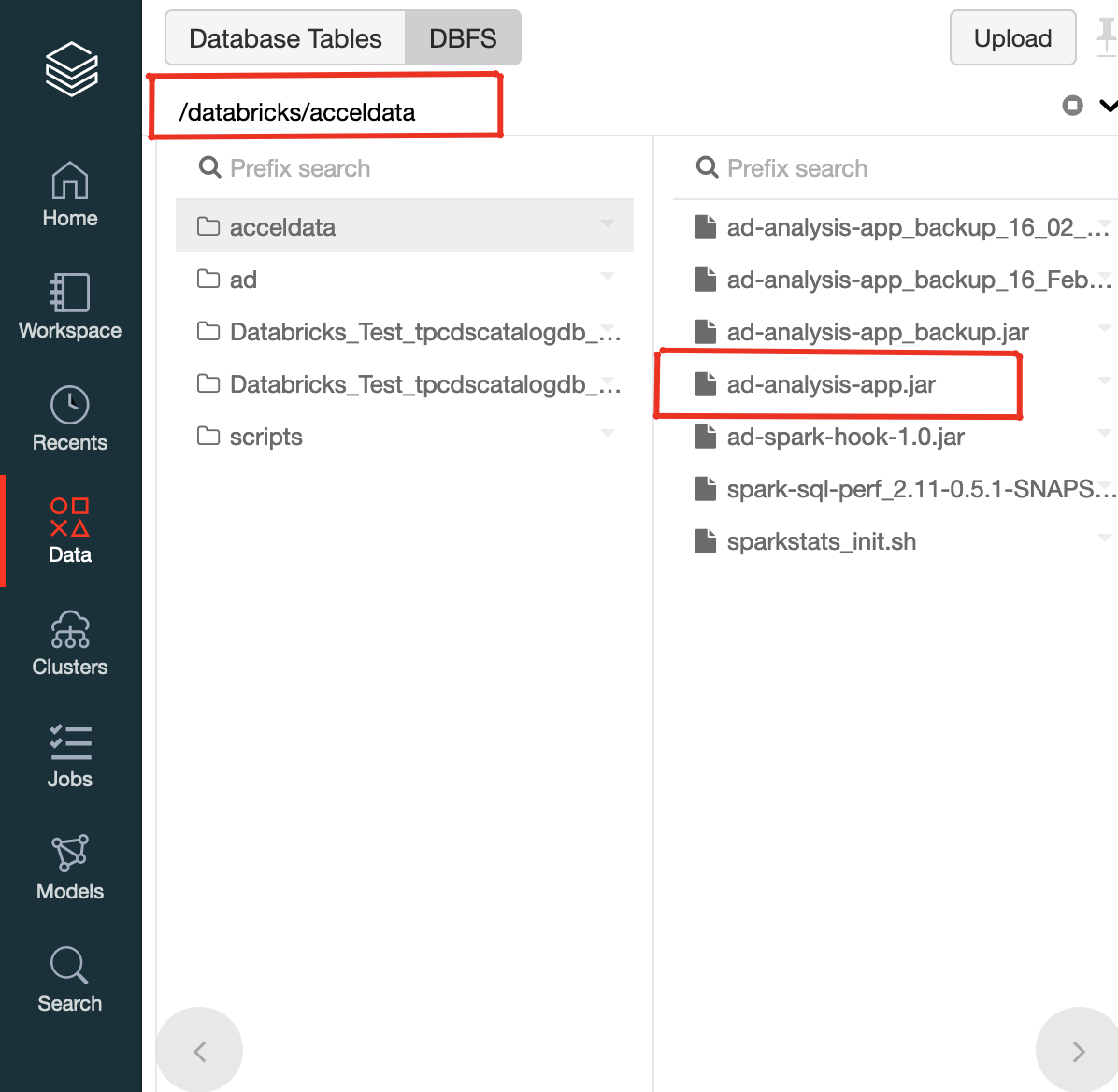
And the PATH of the jar can be obtained by clicking the small down arrow icon besides ad-analysis-app.jar.

The Spark API path format dbfs:/databricks/acceldata/ad-analysis-app.jar is required to set up the jar path later.
Mount S3 bucket to a location on DBFS
To mount S3 bucket to a Databricks cluster execute the below on a Databricks workspace notebook. Go to Workspace ⟶ Users ⟶ Click on small down arrow besides the User ⟶ Create ⟶ Notebook. Paste the below in the notebook, and replace the AccessKey, SecretKey , bucket name with the actual values, and execute the notebook.
val AccessKey = "accesskeyforthes3bucket"val SecretKey = "secretkeyforthes3bucket"val EncodedSecretKey = SecretKey.replace("/", "%2F")val AwsBucketName = "bucketname"val MountName = "results" dbutils.fs.mount(s"s3a://$AccessKey:$EncodedSecretKey@$AwsBucketName", s"/mnt/$MountName")The S3 bucket will now be mounted on DBFS with the path /dbfs/mnt/results.
To facilitate the above steps, a user with permissions to Create files and folders on DBFS can be created, specifically for Torch. Or a user having these permissions need to coordinate with the Torch team.
Once the above steps are completed, the following details need to be shared to configure other torch services:
URL of the Databricks cluster, Cluster ID, UID and Personal Access Token. Example details below,
Databricks Cluster URL: https://dummy.cloud.databricks.comCluster ID: 0811-040399-dummy267. This can be found on the Tags section of the cluster details page UID: tokenPersonal Access Token: Personal Access Token generated on the User Settings PagePath of the ad-analysis-app.jar on DBFS. In the above example dbfs:/databricks/acceldata/ad-analysis-app.jar is the path of the ad-analysis-app.jar.
Path of the S3 mount on DBFS. In the above example /dbfs/mnt/results is the path of the S3 bucket mount on DBFS.
URL for the S3 bucket which is mounted on DBFS (starting with "s3a://") along with AWS Access Key and Secret key to access this S3 location.