Creating Connections
Once you explore a data source and understands its purpose, the next step is to connect to the data source and make most use of its data.
To create a connection, you need to specify the following properties:
- Connection Type: Defines the different set of connections available in a connection to connect to a data asset.
- Connection Details: Includes required details to create a connection to a data source. A connection is always associated to one data asset while a data asset can have more than one connection.
- Analytics Service: The analytics pipeline enables you to view retrieved data like profile information of a data asset, sample data, and tagged data. Analytics pipeline also runs data quality jobs to ensure that the data in the source system is in order.
note
Each analytics service or pipeline needs to be physically connected to the source system.
Create a New Connection
To create a connection, do the following:
Click Data Sources tab. The Create Data Source wizard is displayed.
Select a Data Source type.
Click the Create New tab under Provide Connection Configuration. The table below provides information about the supported connection types and their properties.
Connection Type Description Property 
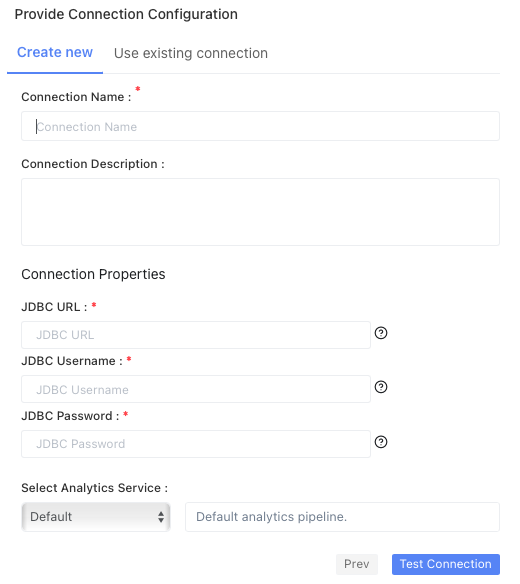
Hive connection connects to a Hive database. - Connection Name: Specify the name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL which is used to locate the database schema. The URL uses the following format:
jdbc:hive2://<hostname>:<port>/<database name>
- JDBC Username: Specify the username to connect to the Hive database.
- JDBC Password: Specify the password to connect to the Hive database.

HBase connection creates a connection for a HBase table. HBase connection is a NoSQL connection. - Connection Name: Specify a name for the connection. It is a required field which is case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters.
- Connection Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- Properties: Drag and drop or click the box to upload the site-config.xml file.

Hadoop Distributed File System (HDFS) connection type accesses data from a hadoop cluster. - Connection Name: Specify the name of the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- Access Id: Specify the access ID.
- Access key: Specify the access key or password.

Amazon Redshift connection allows you to work with data in your cluster by using Amazon Redshift JDBC drivers. - Connection Name: Specify the name of the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL which is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:redshift://<cluster>.<hostname>.<region>.redshift.amazonaws.com:<port>/<database>
-
- JDBC Username: Specify the username to connect to the Redshift database.
- JDBC Password: Specify the password to connect to the Redshift database.

Microsoft JDBC driver is used for SQL server to connect to Azure SQL database. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:sqlserver://[serverName[\instanceName][:portNumber]][;property=value[;property=value]]
-
- JDBC Username: Specify the username to connect to the Azure database.
- JDBC Password: Specify the password to connect to the Azure database.

Snowflake connection type is used to connect to a Snowflake data source. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:snowflake://<accountname>
-
- JDBC Username: Specify the username to connect to the Snowflake database.
- JDBC Password: Specify the password to connect to the Snowflake database.

Amazon Web Services connection type enables AWS integrations. - Connection Name: Name of the connection is a required field that is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- Access Key: Fill in the AWS access key ID.
- Secret Key: Enter the AWS secret access key.
- AWS region: Enter the AWS region for the glue data lake. (example: us-east-1)

Google connection type adds a connection to the Google Cloud Platform (GCP). - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- Credentials File: Locate the service account credentials file and upload it.
- Email: Specify the Google service account email ID.

Kafka connection type accesses streaming data pipelines and data sources. - Connection Name: Name of the connection is a required field that is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- BootStrapServers:
bootstrap.serversis a comma-separated list of bootstrap servers. - Security Protocol: Select one of the security protocols provided like PLAINTEXT(not encrypted) or SASL_PLAINTEXT(encrypted).

MySQL connection type is used to connect to a MySQL database. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:mysql://<server name>/<database name>
-
- JDBC Username: Specify the username to connect to the MySQL database.
- JDBC Password: Specify the password to connect to the MySQL database.

MemSQL connection type is used to connect to a MemSQL database. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:acceldata:mysql://hostname:port;databaseName=<db_name>
-
- JDBC Username: Specify the username to connect to the MemSQL database.
- JDBC Password: Specify the password to connect to the MemSQL database.

POSTGRESQL connection type is used to connect to a POSTGRESQL database. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:postgresql://host:port/database
-
- JDBC Username: Specify the username to connect to the POSTGRESQL database.
- JDBC Password: Specify the password to connect to the POSTGRESQL database.

Oracle connection type is used to connect to an Oracle database. - Connection Name: Specify a name for the connection. It is a required field which is not case sensitive and must be unique in the domain. It should not exceed 128 characters and can contain special characters as well.
- Description: Describe the purpose of the connection. The description cannot exceed 4000 characters.
- JDBC URL: Specify the Java Database Connectivity (JDBC) URL is used to locate the database schema. The JDBC URL has the following format:
-
jdbc:oracle:<drivertype>:@<database>. Example of a driver type is 'Thin'.
-
- JDBC Username: Specify the username to connect to the Oracle database.
- JDBC Password: Specify the password to connect to the Oracle database.
Click Next to select an analytics service for the connection.
Select an Analytics Service from the drop-down list.
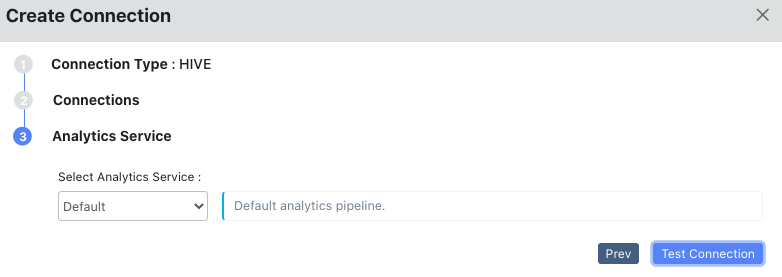
Click Test Connection to check if the connection created is proper.